

Thu, 02/12/2015 - 13:19
1. Introduction
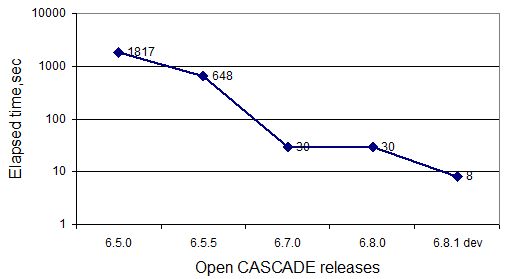
This post in devoted to improvement of performance of building part of Boolean operations. Though in most cases the most time-consuming is intersection part (89% of overall time spent for BO by all Open CASCADE tests), there are special cases where building part takes most of the time. As an example the test case perf bop boxholes is taken, in which relation between Intersection and Building Parts is 2.85 / 26.16. This case is remarkable for showing the performance of the modeler when working with big number of simple shapes.
2. The Case
The Case is perforation of simple flat plate by large number of cylinders (1521). Figure 2.1, 2.2
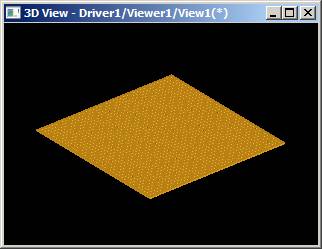 Figure 2.1
Figure 2.1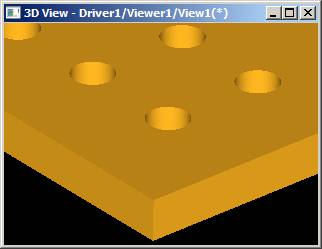 Figure 2.2 The fragment of the result (zoomed).
Figure 2.2 The fragment of the result (zoomed).In terms of the Boolean Operator, the case can be represented as the following:
where R – the result of the operation S1 – the flat plate S2 – the compound of 1521 non-interfered cylinders
3. Analysis and Solution
To find and analyze the "bottlenecks" the IntelВ® Parallel Amplifier was used. Figure 3.1 shows the fragment of the Caller/Callee view of the tool.
 Figure 3.1
Figure 3.1It is evident that the "bottleneck" is in the method FillIn3DParts. This method is preparing the sets of faces that are intended to be internal for the solids of the result. The method can be referred to as auxiliary level of Building Part. The main reason of poor performance here, as it turned out, is in large amount of solids (1522) and faces that are intersected between each other in terms of theirs bounding boxes and, thus, should to be treated by the program in order to detect which faces are inside of which solid. The main idea for acceleration was to perform the computations of loop on solids level in parallel mode using the parallelization schema [2]. The adaptation of existing code to the schema is not complicated and does not require too much code modification. The Figure 3.2 shows the corresponding fragment of the Caller/Callee view, obtained after application of the parallelization schema and internal optimization of the code.
 Figure 3.2
Figure 3.2There are qualitative changes of the performance in the method FillIn3DParts: 6.235s vs. 21.260s (Processor: IntelВ® Core(TM) i5-3450 CPU @ 3.10 GHz, 4 cores). Most part of the code now is performed parallel. The results of the whole case are the following:
- Before optimization: Elapsed time: 28.3 s
- After parallelization and optimization: Elapsed time: 8.3 s
- Gain: 3.4
4. Evolution of Boolean operations relative to the Case
It is interesting to trace the evolution of the performance for various releases of Open CASCADE Technology taking the Case as an example. For comparison the versions 6.5.0, 6.5.5, 6.7.0, 6.8.0, 6.8.1 dev were taken. The following chart illustrates the evolution of the performance of Boolean operator for the Case.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}